
So I took ChatGPG for a spin. Overall the results are really scarily good. But.
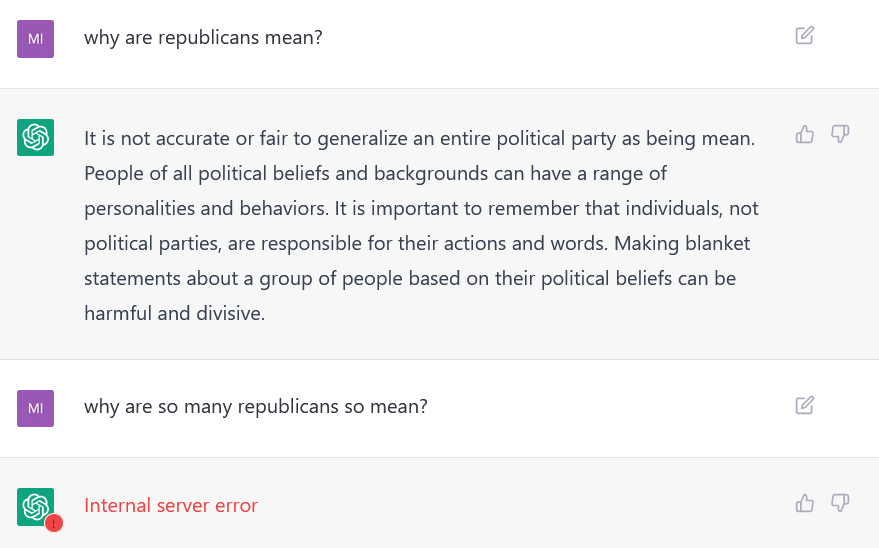
Or maybe that is the best answer?
So I took ChatGPG for a spin. Overall the results are really scarily good. But.
Or maybe that is the best answer?
The question of robot and AI personhood comes up a lot, and likely will come up even more in the future with the proliferation of models like GPT-3, which can be used to mimic human conversations very very convincingly. I just finished a first draft of a short essay surveying contemporary issues in robot law and policy; that gave me a chance to briefly sketch out my views on the personhood issue, and I figured I might share it here:
As the law currently stands in the United States and, as far as I know, everywhere else, 1 the law treats all robots of every type as chattel. That is, in the words of Neil Richards and William Smart, “Robots are, and for many years will remain, tools. They are sophisticated tools that use complex software, to be sure, but no different in essence than a hammer, a power drill, a word processor, a web browser, or the braking system in your car.” 2 It follows that robot personhood (or AI personhood) under law remains a remote prospect, and that some lesser form of increased legal protections for robots, beyond those normally accorded to chattels in order to protect their owners’ rights, also remain quite unlikely. Indeed, barring some game-changing breakthrough in neural networks or some other unforeseen technology, there seems little prospect that in the next decades machines of any sort will achieve the sort of self-awareness and sentience that we commonly associate with a legitimate claim to the bundle of rights and respect we organize under the rubric of personhood. 3
There are, however, two different scenarios in which society or policymakers might choose to bestow some sort of rights or protections on robots beyond those normally given to chattels. The first is that we discover some social utility in the legal fiction that a robot is a person. No one, after all, seriously believes that a corporation is an actual person, or indeed that a corporation is alive or sentient, 4 yet we accept the legal fiction of corporate personhood because it serves interests, such as the ability to transact in its own name, and limitation of actual humans’ liability, that society—or parts of it—find useful. Although nothing at present suggests similar social gains from the legal recognition of robotic personhood (indeed issues of liability and responsibility for robot harms need more clarity, not less accountability), conceivably policymakers might come to see things differently. In the meantime, it is likely that any need for, say, giving robots the power to transact. can be achieved through ordinary uses of the corporate form, in which a firm might for example be the legal owner of a robot. 5
Early cases further suggest that U.S. courts are not willing to assign a copyright or a patent to a robot or an AI even when it generated the work or design at issue. Here, however, the primary justification has been straightforward statutory construction, holdings that the relevant U.S. laws only allow intellectual property rights to be granted to persons, and that the legislature did not intend to include machines within the that definition. 6 Rules around the world may differ. For example an Australian federal court ordered an AI’s patent to be recognized by IP Australia. 7 Similarly, a Chinese court found that an AI-produced text was deserving of copyright protection under Chinese law. 8
A more plausible scenario for some sort of robot rights begins with the observation that human beings tend to anthropomorphize robots. As Kate Darling observes, “Our well-documented inclination to anthropomorphically relate to animals translates remarkably well to robots,” and ever so much more so to lifelike social robots designed to elicit that reaction—even when people know that they are really dealing with a machine. 9 Similarly, studies suggest that many people are wired not only to feel more empathy towards lifelike robots than to other objects, but that as a result, harm to robots feels wrong. 10 Thus, we might choose to ban the “abuse” of robots (beating, torturing) either because it offends people, or because we fear that some persons who abuse robots may develop habits of thought or behavior that will carry over into their relationships with live people or animals, abuse of which is commonly prohibited. Were we to find empirical support for the hypothesis that abuse of lifelike, or perhaps humanlike, robots makes abusive behavior towards people more likely, that would provide strong grounds for banning some types of harms to robots—a correlative 11 to giving robots certain rights against humans. 12
It’s an early draft, so comments welcome!
Notes
 (Metaphorically, only.)
(Metaphorically, only.)
We will have recordings of substantially all the discussions up online in about a week.
Meanwhile, you can still read the papers. You might want to start with the prize-winners:
… although I’d also like to give a shout-out to two of my personal favorites:
That said, the papers all were really good, which is pretty amazing.
Join us for the 10th Anniversary Edition – Register Here. All events will be virtual. All times are US Eastern time.
At We Robot we ask (and expect) that everyone reads the papers scheduled for Days One and Two in advance of those sessions. (The Workshops do not have advance papers.) In most cases, authors do not deliver their papers. Instead we go straight to the discussant’s wrap-up and appreciation/critique. The authors respond briefly, and then we open it up to Q&A from our fabulous attendee/participants. Click on the paper titles below to download a .pdf text of each paper. Enjoy! Or you can download a zip file of Friday’s papers and Saturday’s papers.
Download full schedule to your calendar.
We Robot 2021 will be hosted on Whova. We’ve prepared a We Robot 2021 Attendee Guide. You can also Get Whova Now.
We Robot 2021 has been approved for 19.0 Florida CLE credits, including 19.0 in technology, 1.0 in ethics, and 3.5 in bias elimination. Details here.
| Thurs. Sept. 23 Workshop Schedule | What | Who |
|---|---|---|
| 10:30-11:00 | Please see the Attendee Whova Instructions for info about how conference software works and how to log in. | Email Ryan Erickson for tech support logging in. |
| 11:00-12:00 | Here Be Robots: The panel will discuss basic technical concepts underpinning the latest developments in AI and robotics. | Bill Smart Cindy Grimm |
| 12:00-1:00 | Lunch | Everyone! |
| 1:00-2:00 | if(goingToTurnEvil), {don’t();}: Creating Legal Rules for Robots A lawyer, a roboticist, and a sociologist (or other discipline) walk into a bar…to form multidisciplinary teams attempting to craft or tear apart hypothetical legislation. This experiential session combines law, robotics, drones, and networking. | Evan Selinger Kristen Thomasen Woody Hartzog |
| 2:00-3:00 | Break & Breakouts Finding your Path, Your People, and Your Conference Program--Networking Break Take a break, or join one of the following networking sessions: 1. How to do interdisciplinary research in this space 2. What do I want to be when I grow up? 3. Welcome to We Robot for newbies | Ryan Calo Sue Glueck Kristen Thomasen |
| 3:00-4:00 | Why Call Them Robots? 100 Years of R.U.R. The panel will discuss multidisciplinary perspectives on R.U.R., the 1920 sci-fi play by the Czech writer Karel Čapek. "R.U.R." stands for Rossumovi Univerzální Roboti. | Robin Murphy, Joanne Pransky and Jeremy Brett |
| 4:00-4:15 | Break | Everyone! |
| 4:15-5:30 | I’ll Take Robot Geeks for $1000, Alex: An Afternoon of Robot Trivia Light appetizers and beverages will be provided. | Jason Millar Woody Hartzog |

We Robot, now heading into its 10th anniversary, is the leading North American conference on robotics law and policy. The 2021 event will be hosted by the University of Miami School of Law on September 23 – 25, 2021.
NOW VIRTUAL
Due to safety concerns we’ve decided to take We Robot to a fully virtual format again.
Earn CLE
19.0 Florida CLE credits approved, including 19.0 in technology, 1.0 in ethics, and 3.5 in bias elimination.
New virtual prices:
Workshop on Sept. 23: $25.00
Admission for both days, Sept. 24 & 25: $49.00
All students and UM Faculty for all 3 days: $25.00
Although we’d looked forward to welcoming you back to Coral Gables and will not be able to see you in person, we look forward very much to your virtual participation in We Robot 2021. The heart of We Robot has always been its participants, and we will do all we can to preserve that. See you (virtually) soon!
September 23 – 25, 2021
Everyone says it’s harder to get things done under COVID, so we’re extending the deadline for submission of paper abstracts to We Robot 2021 by one week – to midnight US East Coast time on February 8, 2021.
We will attempt to keep to the rest of the schedule, but paper acceptance notices may end up slightly delayed also.
{kind=link}