So suggests the New York Times in Compact Nuclear Fusion Reactor Is ‘Very Likely to Work,’ Studies Suggest,
Scientists developing a compact version of a nuclear fusion reactor have shown in a series of research papers that it should work, renewing hopes that the long-elusive goal of mimicking the way the sun produces energy might be achieved and eventually contribute to the fight against climate change.
Construction of a reactor, called Sparc, which is being developed by researchers at the Massachusetts Institute of Technology and a spinoff company, Commonwealth Fusion Systems, is expected to begin next spring and take three or four years, the researchers and company officials said.
Although many significant challenges remain, the company said construction would be followed by testing and, if successful, building of a power plant that could use fusion energy to generate electricity, beginning in the next decade.
Before you get too excited, however, consider my previous post on this topic — in 2018, under the headline Fusion Allegedly Just Five Years Away — BBC:
I’ve written before on how fusion power is always coming, never here. About a year and a half ago I posted this:
 Fusion Power is Only 15 Years Away, we’re told. I guess that’s progress since in just the last few years people have said its Always 50 Years Away, or maybe Always 30 Years Away, or maybe formely 30 years away, now its more like 50 years away, or maybe just forever 20 years away, or 13 Years Away.
Fusion Power is Only 15 Years Away, we’re told. I guess that’s progress since in just the last few years people have said its Always 50 Years Away, or maybe Always 30 Years Away, or maybe formely 30 years away, now its more like 50 years away, or maybe just forever 20 years away, or 13 Years Away.
So ten years away is progress, right? Then again three years ago it ten years away so maybe we’re going backwards?
Or maybe we’re looking at the wrong scientific advance here: what we really have is an odd form of time travel?
But comes now the BBC to tell us that according to some startups, maybe fusion power is just five years away, which certainly seems like the frontier is getting closer…or some startups have at least got fusion going on their hype…
I’m sure someday one of these predictions will be right. Someday. Meanwhile, however, the hype frontier has moved back to ten years from five…

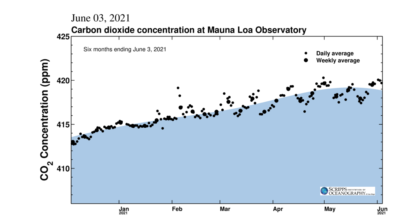 The latest measurement of atmospheric CO2 (as of June 03, 2021): 419.9 ppm; June 2020: 418.32 ppm; 25 years ago: 360 ppm; 250 years ago, est: 250 ppm.
The latest measurement of atmospheric CO2 (as of June 03, 2021): 419.9 ppm; June 2020: 418.32 ppm; 25 years ago: 360 ppm; 250 years ago, est: 250 ppm.
 It is of course no coincidence that shortly after
It is of course no coincidence that shortly after Barring something strange on or after Super Tuesday, I plan to vote for Warren in the upcoming Florida primary. In primaries you vote your heart, in the general election you vote you head. Warren is the candidate whose speeches — and whose policies — inspire. I think she’d be a terrific Chief Executive. Sanders has virtues, and I’m grateful that he moved the Overton Window. I’m sure he’d be infinitely better than Trump, but I have some pretty big doubts as to how effective he’d be as an executive.
Barring something strange on or after Super Tuesday, I plan to vote for Warren in the upcoming Florida primary. In primaries you vote your heart, in the general election you vote you head. Warren is the candidate whose speeches — and whose policies — inspire. I think she’d be a terrific Chief Executive. Sanders has virtues, and I’m grateful that he moved the Overton Window. I’m sure he’d be infinitely better than Trump, but I have some pretty big doubts as to how effective he’d be as an executive.{kind=link}